

Por Fernando Camarena, Ricardo Cuevas, Miguel González y Leonardo Chang
En algún punto de nuestra vida hemos tenido el sueño, ¿O temor?, de que aquello que llamábamos ficción se convierta en una realidad. ¿Será la intersección entre la visión por computadora (CV) y la inteligencia artificial (AI) la clave para este camino?
Muy probablemente, sin darnos cuenta, ya hemos sido beneficiados por estas tecnologías. Al tomar nuestro teléfono celular, tenemos aplicaciones de CV y AI que van desde un sistema biométrico de reconocimiento facial hasta la modificación de imágenes digitales mediante filtros fotográficos, utilizados ampliamente en redes sociales.
Sin embargo, el impacto y límite de aplicación está lejos de ser alcanzado. A través de sus programas de posgrado, el Tecnológico de Monterrey impulsa la sinergia entre estudiantes y profesores investigadores para el desarrollo de aplicaciones con potencial transformador. Dentro de la línea de investigación de aprendizaje automático (Machine Learning), encontramos diferentes proyectos, incluyendo la videovigilancia inteligente, mismos que se aplican tanto a nivel teórico como práctico.
La videovigilancia inteligente tiene el objetivo de otorgar “capacidades” a las videocámaras, incluyendo la detección de anomalías, peleas, armas o accidentes. Para lograrlo, se necesita enseñarle a una computadora a ver y entender su entorno visual. Pero, ¿Cómo podemos hacer esto? En este artículo hablaremos del proceso de cómo un ordenador reconoce la acción humana en videos.

El primer paso es entender qué es una acción; imaginemos que saludamos a una persona. Probablemente, la imagen mental creada involucra el característico movimiento de la mano y es que de forma inconsciente solemos asociar un mensaje a una secuencia de gestos. Es precisamente a esta secuencia codificada a lo que llamaremos «Acción».
Ahora que ya entendemos qué queremos reconocer, nos enfocaremos en explicar de forma breve cómo se forma una imagen digital. Una cámara está equipada con diversos sensores sensibles a la luz visible. Cada uno de estos sensores tiene múltiples «píxeles» acomodados en una retícula. Cada uno de los píxeles produce una carga eléctrica proporcional a la cantidad de luz que recibe, carga que estará en un rango de 0 a 255. En otras palabras, una imagen digital es una matriz que contiene valores entre 0 y 255, como se muestra en la figura 1.

Un video es tan solo una secuencia de imágenes que puede ser usada para reconocer una acción. El método propuesto por nuestro grupo de investigación en el Tecnológico de Monterrey contempla 3 pasos:
- Caracterización del video
- Entrenar un modelo de inteligencia artificial
- Inferencia del modelo de inteligencia artificial
Caracterización del video
Dos personas que no hablan el mismo idioma necesitan de un artefacto traductor que les permita entenderse. Esto mismo ocurre en las computadoras, es necesario transformar los datos para que una computadora pueda entender de la mejor manera el concepto de acción.
A esto paso lo llamaremos «caracterización del video» y lo dividiremos en tres sub-pasos: muestreo, seguimiento y observación. El muestreo consiste en saber qué partes de la imagen vamos a analizar. La opción trivial consiste en examinar toda la matriz de información, pero el cómputo será tardado e innecesario. Entonces, una mejor manera es identificando las locaciones de interés. En el enfoque propuesto, sugerimos que estimar la pose humana ayuda a disminuir el espacio de búsqueda, como se muestra en la figura 2.

En este punto, tenemos las locaciones que el algoritmo usará. Pero, un video es un conjunto de imágenes, por lo tanto, el siguiente paso consiste en saber las locaciones de interés a lo largo de todo el video. Esto suele hacerse mediante el uso de algoritmos de flujo óptico, cuya idea intuitiva se encuentra expresada en la figura 3.

Al aplicar el algoritmo de flujo óptico en cada una de las imágenes, tendremos una secuencia en el tiempo de locaciones. A esta secuencia se le denominará «trayectoria». Se tendrá una trayectoria por cada región de interés analizada, como se muestra en la figura 4.
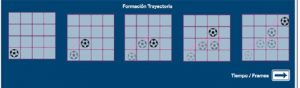
La observación es el último sub-paso y es un proceso que consiste en responder preguntas acerca del espacio y tiempo en el que se ubica la trayectoria. Por ejemplo, ¿Cómo fue el movimiento de la trayectoria?, ¿En qué región sucedió el movimiento? Este tipo de preguntas puede ser contestada mediante histogramas aplicados tanto a la forma, como al flujo.
Entrenar un model

En este momento, tenemos un conjunto de observaciones por video. Pero, para que una computadora pueda aprender, es necesario entrenar un modelo de inteligencia artificial (AI). Una analogía sencilla es la construcción de objetos usando arcilla.
La arcilla cruda representa un modelo de AI, que en un principio no tiene forma alguna. Dependiendo de lo que queramos, le daremos forma de un jarrón, un florero o cualquier otro objeto de nuestra elección. Al proceso de formar el objeto se le conoce como algoritmo de entrenamiento. Este algoritmo toma un «concepto» en forma de observaciones y con ello se construye la información requerida. En este caso, las observaciones son las trayectorias extraídas en el paso anterior.
La literatura del tema ofrece múltiples algoritmos de entrenamiento con diferentes ventajas y desventajas, pero uno de los más conocidos es mediante las técnicas de bolsa de palabras y máquinas de soporte vectorial. Explicar la matemática detrás de estas técnicas puede resultar un tanto complejo, pero la idea intuitiva es encontrar patrones del tipo:
“Las trayectorias de la acción caminar ocurren en la parte inferior de la imagen. Por lo contrario, en la acción de saludar el movimiento ocurre en la parte superior”.
Inferencia del modelo de AI
Regresando a nuestra analogía de la arcilla, una vez modelado el objeto, el siguiente paso consiste en usar dicho objeto. A esto se le conoce como inferencia de un modelo, en otras palabras, usarlo para lo que fue creado. Un ejemplo de inferencia, es utilizar estos modelos en la red de cámaras del Tecnológico de Monterrey para identificar posibles incidentes dentro de algún campus.
La información descrita nos da una idea de cómo una computadora puede detectar una acción. Pero, aún hay varios retos relacionados a la vasta diversidad y formas que un sujeto puede desempeñar una acción y a las limitaciones de la cámara.
¿Quieres saber más?
Para más información sobre este trabajo, te invitamos a consultar los siguientes artículos de investigación:
Camarena, F., Chang, L., Gonzalez-Mendoza, M., & Cuevas-Ascencio, R. J. (2022). Action recognition by key trajectories. Pattern Analysis and Applications, 1-15.
Camarena, F., Chang, L., & Gonzalez-Mendoza, M. (2019, May). Improving the dense trajectories approach towards efficient recognition of simple human activities. In 2019 7th International workshop on biometrics and forensics (IWBF) (pp. 1-6). IEEE.
Autores
Fernando Camarena
Fernando Camarena es candidato a Doctor en Ciencias Computacionales por el Tecnológico de Monterrey. Su Investigación se centra en el aprendizaje autosupervisado para tareas relacionadas con videos.
Ricardo Cuevas
Ricardo Cuevas es candidato a Doctor en Ciencias Computacionales por el Tecnológico de Monterrey por su investigación en el área de la visión por computadora. Ricardo es ingeniero en mecatrónica y actualmente se desempeña como desarrollador web Full Stack.
Miguel González Mendoza
Miguel González Mendoza es Doctor en Inteligencia Artificial del Instituto Nacional de las Ciencias Aplicadas en Toulouse, Francia y es Profesor Investigador del Departamento de Computación del Tecnológico de Monterrey. Es Investigador Nacional Nivel II.
Leonardo Chang
Leonardo Chang es Doctor en Ciencias Computacionales por el Instituto Nacional de Astrofísica, Óptica y Electrónica de México. Fue Investigador en el Centro de Aplicaciones de Tecnologías de Avanzada en Cuba de 2007 a 2017 y Profesor Investigador del Departamento de Computación del Tecnológico de Monterrey de 2017 a 2022. Es Investigador Nacional Nivel I.

















