

Por Víctor Sosa y Raúl Monroy
La inteligencia artificial es un tema del cual ya estamos más que acostumbrados a escuchar, leer, y hablar en nuestro día a día. Actualmente, las redes sociales, la industria, y la academia son ejemplos claros de un desbordamiento en menciones y referencias a la inteligencia artificial. Lo cual se debe a la aplicación de varias técnicas de inteligencia artificial para el mejoramiento de nuestra vida cotidiana. Dentro de la inteligencia artificial, las técnicas de aprendizaje automático han sido de gran interés para expertos de diversos dominios como la medicina, finanzas, gobierno, entre otros, específicamente para producir modelos inteligentes que apoyen la toma de decisiones.
Las redes neuronales, las máquinas de vector de soporte y los bosques de decisión han demostrado a través de varios estudios ser técnicas que producen modelos con un mejor desempeño en tareas de clasificación, apoyo fundamental a la toma de decisiones. De igual forma, los modelos generados por árboles de decisión alcanzan un desempeño competitivo considerando las técnicas anteriores, pero además brindan información relevante sobre las razones del resultado obtenido.
Diariamente, enfrentamos diversas situaciones, en las que debemos tomar decisiones. Éstas van desde determinar qué desayunamos, o qué ropa vamos a vestir. Pero, en situaciones menos triviales, un cirujano médico debe resolver si operar o no a un paciente, o el tratamiento que debe prescribir; similarmente, un mecánico, en la reparación de un automóvil, debe determinar si debe cambiar o no una pieza de un auto o diagnosticar correctamente el desperfecto de dicho auto. Cada proceso de toma de decisiones puede estar acompañado por una explicación del porqué de nuestra decisión. Por ejemplo, cuando vamos al médico, debido a un dolor o malestar, normalmente le pedimos un diagnóstico de nuestro padecimiento, con la intención de conocer qué lo origina y cómo actuar para corregir la situación. Incluso, existen problemas en los que legalmente, no podemos identificar una solución sin tener una explicación, por ejemplo, en la identificación de fraudes y concesión de créditos. Dado lo anterior, surge el concepto de inteligencia artificial explicable (XAI) que tiene como objetivo desarrollar modelos que puedan ser comprensibles y transparentes para expertos y usuarios de diferentes dominios sin sacrificar el rendimiento del modelo.
Modelos exactos, pero ¿y las razones de la decisión?
Una red neuronal y una máquina de vector de soporte pueden determinar un posible diagnóstico para alguna enfermedad, como el cáncer, en función de datos provenientes del historial médico de un paciente con un alto porcentaje de exactitud. Sin embargo, la salida del modelo es incapaz de decirnos las razones del diagnóstico. A los modelos que no proporcionan ninguna explicación del resultado obtenido les llamaremos de caja negra. Si como usuarios o expertos lo que nos interesa es la decisión dentro de un proceso de clasificación, más que las razones, entonces indudablemente las redes neuronales, o máquinas de vector de soporte o los bosques decisión nos ayudarían a tener el resultado que esperamos. Finalmente, puede haber una confusión de que los bosques de decisión tengan el mismo funcionamiento que los árboles, sin embargo, para tomar una decisión final se consideran varios de resultados de árboles independientes y se somete a un proceso de votación lo que hace complejo determinar el origen de la decisión.
Modelos competitivos acompañados de una explicación
Ahora bien, si lo que nos interesa como usuarios o expertos de un modelo inteligente es que la decisión tomada esté acompañada de una explicación entonces debemos utilizar otras técnicas de aprendizaje automático de caja blanca. Como sabemos la toma de decisiones implica que se debe analizar cuidadosamente los diferentes escenarios de un resultado de clasificación por las consecuencias que pueden implicar. Por ejemplo, considera que estamos analizando una serie de tweets y deseamos saber por qué pueden ser o no nocivos para un público infantil. Dada la situación anterior, esperaríamos que una técnica de aprendizaje automático deba generar un modelo que produzca no solo una decisión, sino también una explicación que a la vez se exprese en un lenguaje que el usuario del modelo pueda comprender. Este escenario es algo complejo puesto que básicamente es preguntarle a la computadora el porqué de su decisión y que no solo nos responda con ceros y unos sino con una respuesta que podamos entender. En palabras más simples, la máquina o entidad artificial debe explicarnos su decisión, como se ilustra en la Figura 1, situación que incluso en nuestros días puede tomarse como película de ciencia ficción.

Una de las técnicas de caja blanca más relevantes dentro del aprendizaje automático son los árboles de decisión. Estos tienen las características de generar modelos que son capaces de explicar la decisión que producen, a través de condiciones que forman reglas que nos ayudan a determinar por qué una entrada nos dio una determinada salida. Además, dichas condiciones pueden ser explicadas en términos que una persona pueda entender.
Los modelos generados por los árboles de decisión aparte de explicar el resultado son capaces de considerar datos de entrada que sean representadas por números (temperatura, número de células, oscilaciones de un motor, gasto de combustible, edad) o categorías (color de un objeto, estado del clima, tipo de consistencia, deporte favorito, preferencias), e incluso valores faltantes, lo cual lo hace robusto para los diversos valores que pudieran ser las entradas del modelo.
¿Cómo es que los árboles de decisiones nos pueden dar una explicación?
Los árboles de decisión pueden entregarnos una explicación de las decisiones que toman debido a la forma en que son construidos. A diferencia de las redes neuronales o las máquinas de soporte vectorial que ajustan valores numéricos para procesar entrada por entrada, los árboles de decisión dividen los datos en particiones utilizando reglas hasta que no quede ninguna entrada por procesar.
Para entender de mejor manera este proceso toma en consideración la siguiente base de datos en la Figura 3.
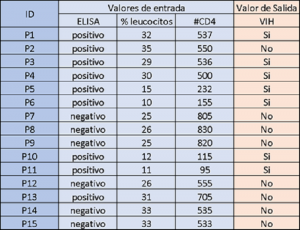
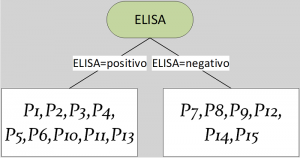
El proceso de construcción empieza por seleccionar un atributo de los posibles valores de entrada (columnas), es decir, de acuerdo con la Figura 3: ELISA, % leucocitos y #CD4. Posteriormente, se establece una posible condición para dividir el total de las personas en dos o más grupos (partición), por ejemplo: “ELISA igual a positivo” y su complemento “ELISA igual a negativo», entre otras. En la Figura 4 se ilustra un ejemplo de las particiones generadas por las condiciones anteriores y que objetos (filas) quedan en cada partición.
Si bien se pueden generar un gran número de reglas que dan lugar a un gran número de particiones a las que llamaremos candidatas, este proceso es automático. Para que se pueda seleccionar una partición candidata se utiliza una medida evaluadora la cual determina que partición es la mejor. Por lo que en cada nodo se evaluarán las particiones generadas para seleccionar la mejor en función de la medida evaluadora. Este proceso se realiza por cada nodo generado hasta que ya solo queden objetos de un solo valor de salida en cada partición, ya sean personas con VIH o sin el virus, pero sin mezclarse. También, otro criterio de paro es que ya solamente quedé una sola entrada por lo que ya no podría dividirse más la información. El proceso de partición y selección de atributos se repite hasta dividir completamente la base de datos de entrada dando lugar al árbol de decisión final como se muestra en la Figura 5.
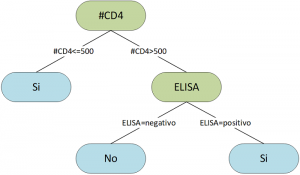
El modelo generado por el árbol de decisión de la Figura 5 ahora tiene la capacidad de determinar si un paciente del que acaban de llegar sus análisis de sangre tiene VIH o no. Por ejemplo, si llega un paciente con #CD4 en 119 inmediatamente la respuesta del modelo es que el paciente podría tener VIH por lo cual se tendría que informar al médico para validar la decisión. Esta decisión vendría acompañada de información valiosa como que la persona tiene sus niveles de #CD4 fuera de lo normal. En otro caso si la persona tiene #CD4 en 560 y ELISA en negativo entonces la respuesta del modelo sería sin VIH esto gracias a que #CD4 y ELISA están dentro de los valores esperados. Esta información sobre las decisiones del modelo ayuda a los expertos a comprender de mejor manera el porqué.
Conclusiones
En la actualidad, la necesidad de conocer una explicación del porqué de las decisiones tomadas por un modelo inteligente en las diversas aplicaciones relacionadas con la inteligencia artificial ha cobrado gran relevancia. Esto no solamente por el valor que pueda generar el uso de modelos inteligentes, sino porque como personas deseamos conocer las razones que conllevaron a la toma de una decisión. Con el incremento de máquinas inteligentes la necesidad del ser humano de conocer lo que hay detrás de una recomendación, clasificación y juicio que emite una máquina inteligente se ha vuelto más importante debido a su uso generalizado en nuestras actividades diarias. Si bien dentro de la inteligencia artificial existen técnicas que se focalizan en tener el mejor desempeño en la tarea de clasificación, hay otras como los árboles de decisión que mantienen un balance entre un buen desempeño y una explicación al grado que pueda entender el usuario del modelo. Por lo tanto, siempre es una buena práctica analizar la aplicación final de un determinado modelo inteligente para que escojamos correctamente la técnica que va a ayudarnos a generarlo.
¿Quieres saber más sobre los árboles de decisión?
Te invitamos a revisar nuestro tutorial práctico sobre árboles de decisión desde cualquier red institucional:
Víctor Adrián Sosa Hernández, Raúl Monroy, Miguel Angel Medina-Pérez, Octavio Loyola-González, and Francisco Herrera. A Practical Tutorial for Decision Tree Induction: Evaluation Measures for Candidate Splits and Opportunities. ACM Comput. Surv. 54, 1, Article 18 (January 2022), 38 pages. https://doi.org/10.1145/3429739
Autores
Víctor Adrián Sosa Hernández, obtuvo el grado de doctor en ciencias en computación, por el CINVESTAV (2017). Es profesor de tiempo completo del departamento de computación en el Tecnológico de Monterrey campus Estado de México, Investigador nacional nivel candidato, miembro adherente de la Academia Mexicana de Computación.
Raúl Monroy, obtuvo el grado de doctor en Inteligencia Artificial, por la universidad de Edimburgo (1998). Es profesor investigador titular en el Tecnológico de Monterrey; Investigador nacional nivel 3, miembro de la Academia Mexicana de Ciencias y miembro constituyente de la Academia Mexicana de Computación. En el Tecnológico de Monterrey es director de los programas de posgrado en ciencias computacionales, región CDMX, y líder del grupo de investigación con enfoque estratégico en modelos de aprendizaje computacional.

















